4 Visualizing Data
4.1 Building plots
There are multiple approaches to data visualisation in R; in this course we will use the popular package ggplot2, which is part of the larger tidyverse collection of packages. A grammar of graphics (the "gg" in "ggplot") is a standardised way to describe the components of a graphic. ggplot2 uses a layered grammar of graphics, in which plots are built up in a series of layers. It may be helpful to think about any picture as having multiple elements that sit semi-transparently over each other.
Figure 1 displays the steps to create a simple scatterplot using this layered approach. First, the plot space is built (layer 1); the variables are specified (layer 2); the type of visualisation (known as a geom) that is desired for these variables is specified (layer 3) - in this case geom_point() is called to visualise individual data points; a second geom is added to include a line of best fit (layer 4), the axis labels are edited for readability (layer 5), and finally, a theme is applied to change the overall appearance of the plot (layer 6).
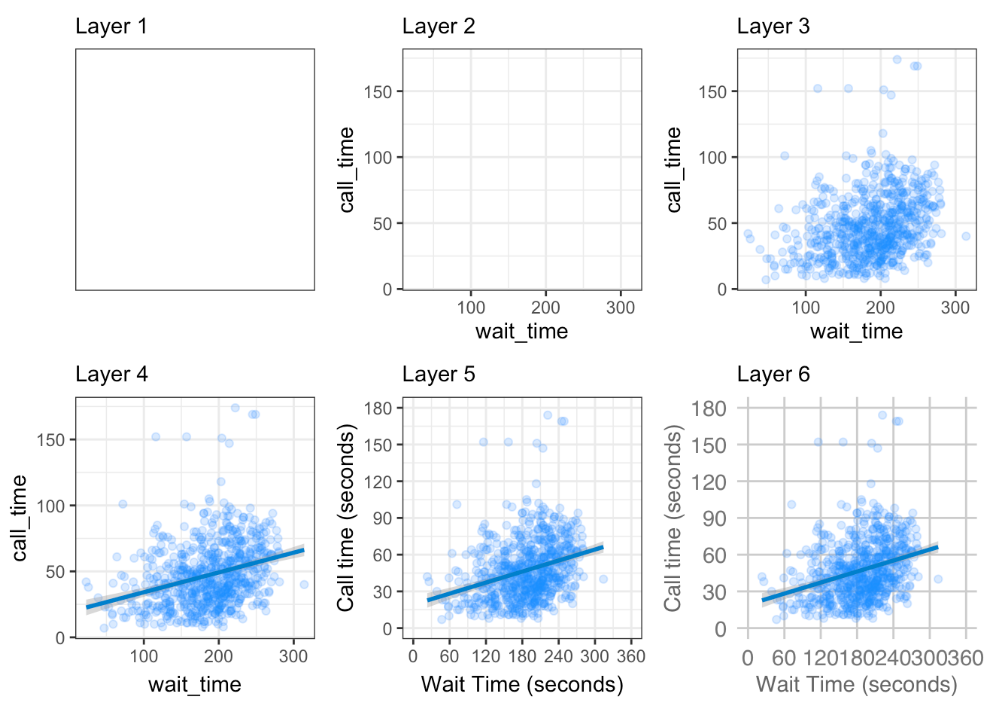
Figure 4.1: Figure 1: Steps to create a layered plot
Importantly, each layer is independent and independently customisable. For example, the size, colour and position of each component can be adjusted. The use of layers makes it easy to build up complex plots step-by-step, and to adapt or extend plots from existing code.
Using the concept of building up a plot by layers, we will describe some specific plot types. Different types of data require different types of plots, so the following sections are organised by data type.
The ggplot2 cheat sheet is a great resource to help you find plots appropriate to your data, based on how many variables you're plotting and what type they are. The examples below all use the GBBO data, but each plot communicates something different.
We don't expect you to memorise all of the plot types or the methods for customising them, but it will be helpful to try out the code in the examples below for yourself, changing values to test your understanding.
4.2 Counting categories
4.2.1 Bar plot
If you want to count the number of things per category, you can use geom_bar(). You only need to provide a x mapping to geom_bar() because by default geom_bar() uses the number of observations in each group of x as the value for y, so you don't need to tell it what to put on the y-axis.
ggplot(ratings, aes(x = channel)) +
geom_bar()
Notice that layers are added using the plus + symbol at the end of the previous line, not at the start of the next line. For example if you make this mistake:
ggplot(ratings, aes(x = channel))
+ geom_bar()...it will produce an empty 'base layer' and then an error like this:

## Error:
## ! Cannot use `+.gg()` with a single argument. Did you accidentally put + on a new line?
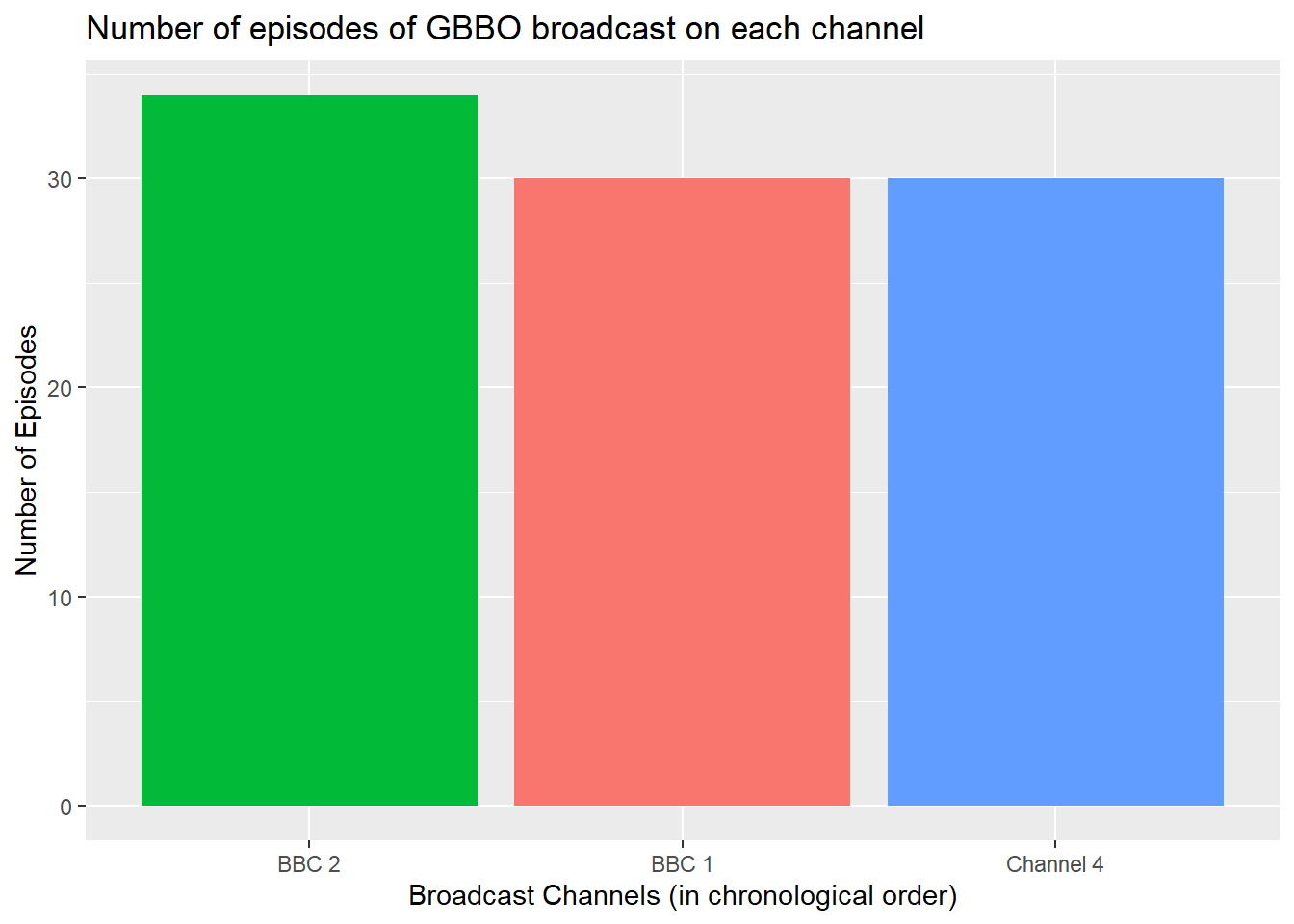
- Inspect the code below and try running it layer by layer to figure out how things like the order of the columns and their labels change.
ggplot(ratings, aes(x = channel,
fill = channel)) +
geom_bar() +
labs(title="Number of episodes of GBBO broadcast on each channel")+ # adds a plot title
ylab("Number of Episodes")+ # adds an axis label
theme(legend.position = "none")+ # removes the legend
scale_x_discrete(
# change axis label
name = "Broadcast Channels (in chronological order)",
# change to chronological order
limits = c("BBC2", "BBC1", "C4"),
# change labels
labels = c("BBC 2", "BBC 1", "Channel 4")
)
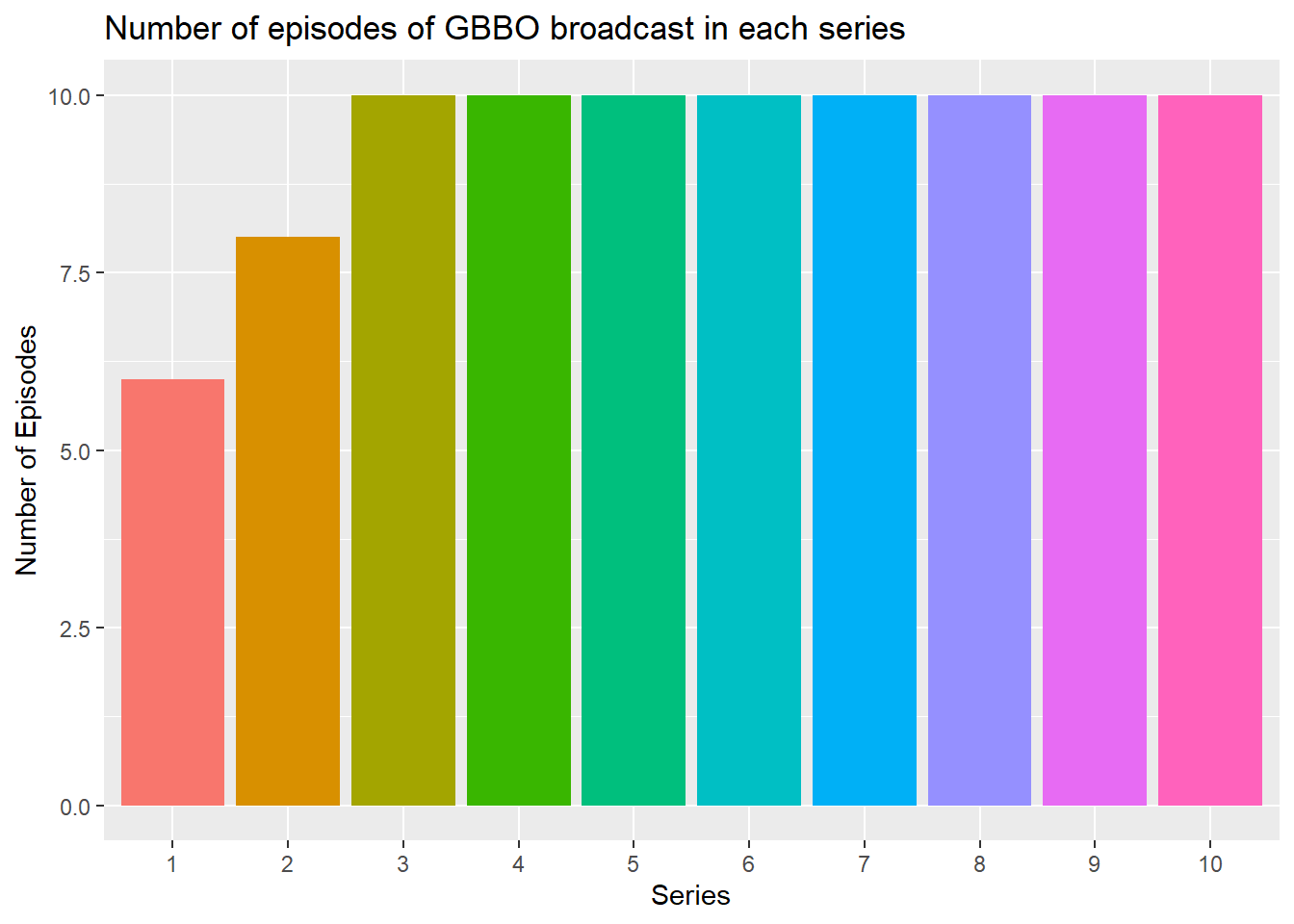
- Copy and edit the code above to produce a bar plot showing the number of episodes in each series of GBBO
ggplot(ratings, aes(x = series,
fill = series)) +
geom_bar() +
labs(title="Number of episodes of GBBO broadcast in each series")+ # adds a plot title
ylab("Number of Episodes")+ # adds an axis label
xlab("Series")+ # adds an axis label
theme(legend.position = "none")+ # removes the legend
scale_x_discrete(
# change to categorical labels
limits = c("1", "2", "3", "4", "5", "6", "7", "8", "9", "10"),
# change labels
labels = c("1", "2", "3", "4", "5", "6", "7", "8", "9", "10")
)
4.2.2 Column plot
If your data already have a column with the number you want to be the height of each bar or column, you can use geom_col() to plot it. Recall that the ratings data contains the variable viewers_7day which contains the number of viewers in the 7 days after each episode which we can plot as the height of each bar/column by setting y=viewers_7day. But what will we use to define where they are plotted on the x-axis?
After considering the values contained in the variable
seriesand/orepisodecomplete this statement:Neither the values in
seriesorepisodecan be used to definex=:
select(ratings,series,episode)## series episode
## 1 1 1
## 2 1 2
## 3 1 3
## 4 1 4
## 5 1 5
## 6 1 6
## 7 2 1
## 8 2 2
## 9 2 3
## 10 2 4
## 11 2 5
## 12 2 6
## 13 2 7
## 14 2 8
## 15 3 1
## 16 3 2
## 17 3 3
## 18 3 4
## 19 3 5
## 20 3 6
## 21 3 7
## 22 3 8
## 23 3 9
## 24 3 10
## 25 4 1
## 26 4 2
## 27 4 3
## 28 4 4
## 29 4 5
## 30 4 6
## 31 4 7
## 32 4 8
## 33 4 9
## 34 4 10
## 35 5 1
## 36 5 2
## 37 5 3
## 38 5 4
## 39 5 5
## 40 5 6
## 41 5 7
## 42 5 8
## 43 5 9
## 44 5 10
## 45 6 1
## 46 6 2
## 47 6 3
## 48 6 4
## 49 6 5
## 50 6 6
## 51 6 7
## 52 6 8
## 53 6 9
## 54 6 10
## 55 7 1
## 56 7 2
## 57 7 3
## 58 7 4
## 59 7 5
## 60 7 6
## 61 7 7
## 62 7 8
## 63 7 9
## 64 7 10
## 65 8 1
## 66 8 2
## 67 8 3
## 68 8 4
## 69 8 5
## 70 8 6
## 71 8 7
## 72 8 8
## 73 8 9
## 74 8 10
## 75 9 1
## 76 9 2
## 77 9 3
## 78 9 4
## 79 9 5
## 80 9 6
## 81 9 7
## 82 9 8
## 83 9 9
## 84 9 10
## 85 10 1
## 86 10 2
## 87 10 3
## 88 10 4
## 89 10 5
## 90 10 6
## 91 10 7
## 92 10 8
## 93 10 9
## 94 10 10# Notice that neither series nor episode contain unique values, which would be necessary to define the position on the x-axis for each of the columns with height equal to the ratings (viewers_7day)So before we can create the column plot, we need to create a new variable:
- Run this code to create a new variable
ep_idwhich is the unique index indicating the chronological order of each episode (using therow_number()function and the fact that it's the same as the order it appears in theratingsdata).
ratings <- ratings %>% mutate(ep_id = row_number())Now we have the two variables we need to make the column plot.
- Inspect and run this code to produce the plot below.
ggplot(ratings, aes(x = ep_id, y = viewers_7day, fill = series)) +
geom_col() +
labs(title="7-Day Viewers across All Series/Episodes")+
ylab("Number of viewers (millions)")+ # adds an axis label
xlab("Episode Index")+ # adds an axis label
scale_fill_discrete(name="Series") # set the name of the legend 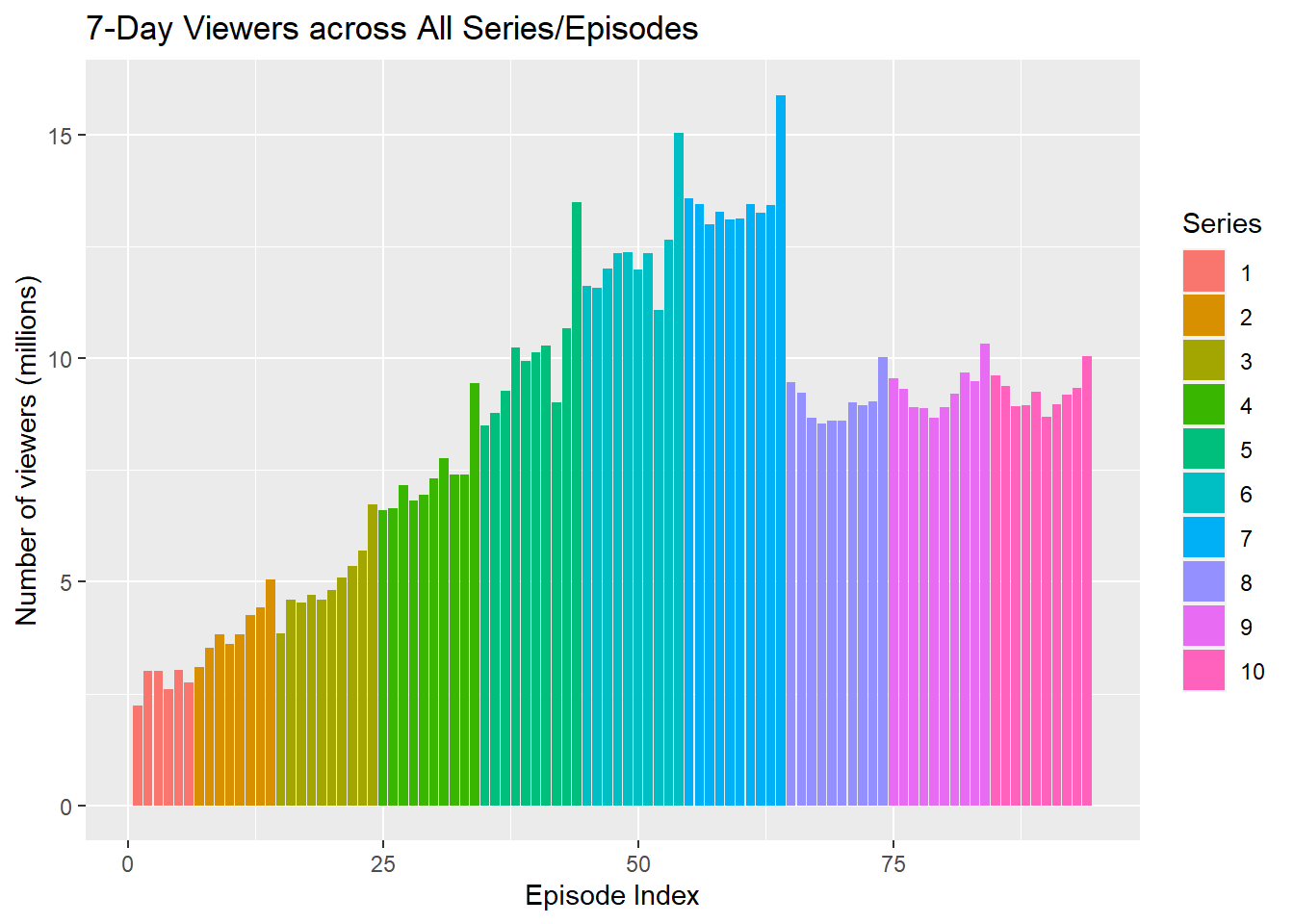
4.2.4 Test your understanding
Here is a small data table.
| country | population | island |
|---|---|---|
| Northern Ireland | 1,895,510 | Ireland |
| Wales | 3,169,586 | Great Britain |
| Republic of Ireland | 4,937,786 | Ireland |
| Scotland | 5,466,000 | Great Britain |
| England | 56,550,138 | Great Britain |
- What geom would you use to plot the population for each of the 5 countries?
- What mapping would you use?
- What geom would you use to plot the number of countries on each island?
- What mapping would you use?
4.3 One continuous variable
If you have a continuous variable, like the number of views 7 days after each broadcast, you can use geom_histogram() or geom_density() to show the distribution. Just like geom_bar() you are only required to specify the x variable.
4.3.1 Histogram
A histogram splits the data into "bins" along the x-axis and shows the count of how many observations are in each bin along the y-axis.
ggplot(ratings, aes(x = viewers_7day)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.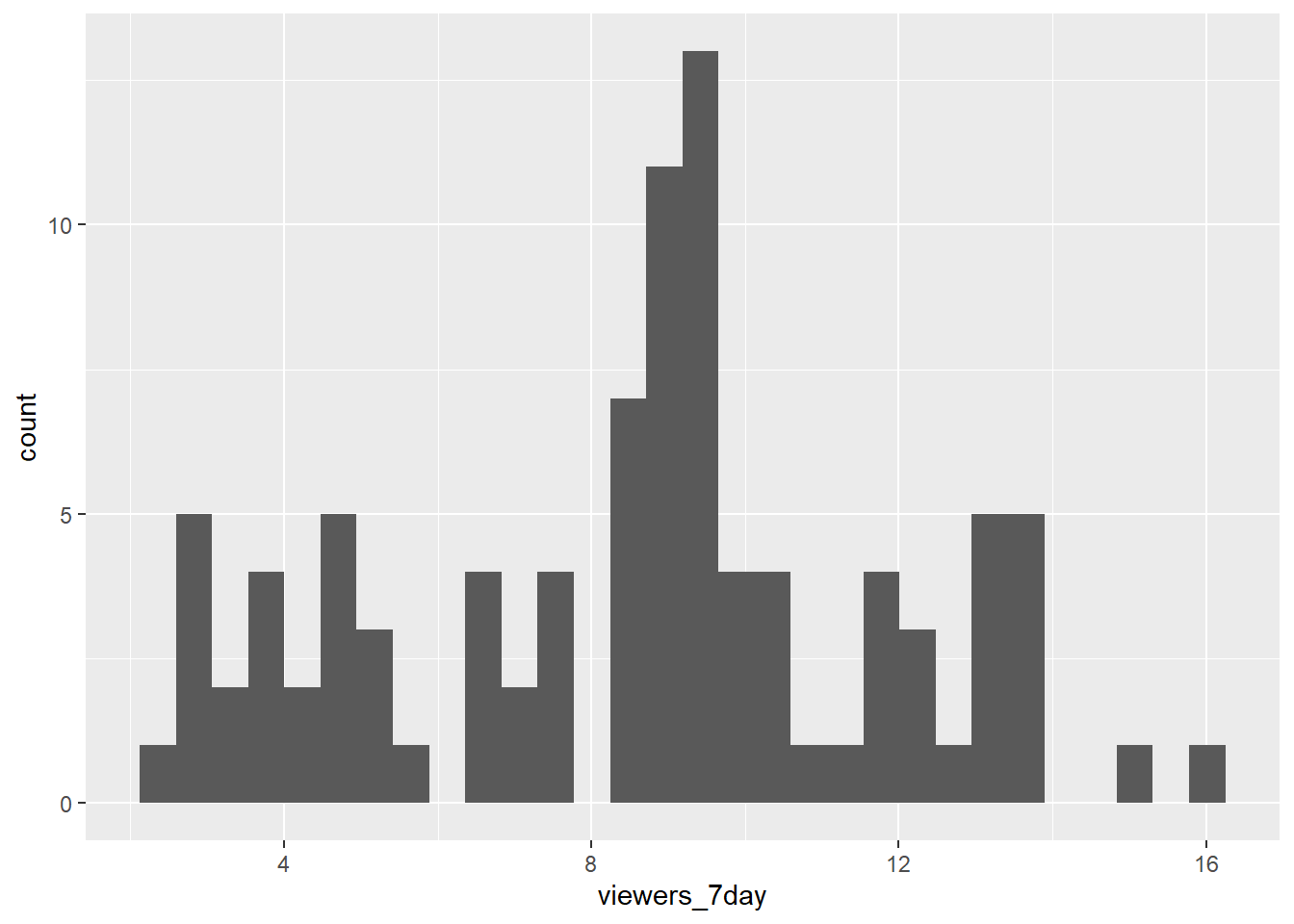
Figure 4.2: Histogram of ratings.
You should always set the binwidth or number of bins to something meaningful for your data (otherwise you get an annoying message, like the one above). You might need to try a few options before you find something that looks good and conveys the meaning of your plot.
- Try changing the values of
binwidthandbinsbelow to see what works best.
# adjust width of each bar
ggplot(ratings, aes(x = viewers_7day)) +
geom_histogram(binwidth = 2)
# adjust number of bars
ggplot(ratings, aes(x = viewers_7day)) +
geom_histogram(bins = 5)Finally, the default style of grey bars is ugly, so you can change that by setting the fill and colour, as well as using scale_x_continuous() to update the axis labels.
- Adapt and run this code to control the appearance of the histogram
ggplot(ratings, aes(x = viewers_7day)) +
geom_histogram(binwidth = 1,
boundary = 0,
fill = "white",
color = "black") +
scale_x_continuous(name = "Number of viewers 7 days after broadcast (in millions)")ggplot(ratings, aes(x = viewers_7day)) +
geom_histogram(binwidth = 1,
boundary = 0,
fill = "white",
color = "black") +
scale_x_continuous(name = "Number of viewers 7 days after broadcast (in millions)")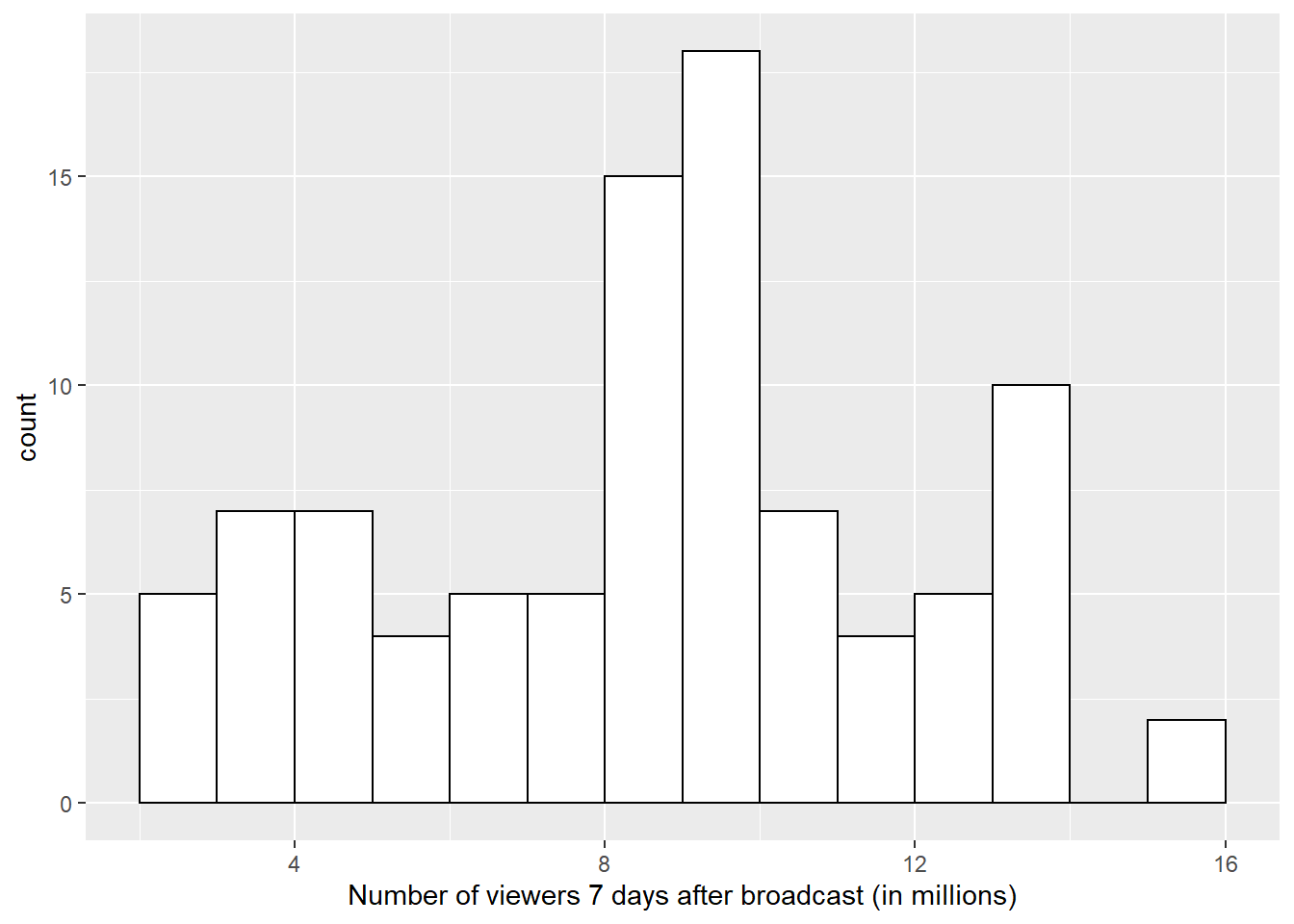
4.4 Grouped continuous variables
There are several ways to compare continuous data across groups. Which you choose depends on what point you are trying to make with the plot.
4.4.1 Subdividing distributions
In previous plots, we have used fill purely for visual reasons, e.g., we have changed the colour of the histogram bars to make them look nicer. However, you can also use fill to represent another variable so that the colours become meaningful.
Setting the fill aesthetic in the mapping will produce different coloured bars for each category of the fill variable, in this case issue_category.
ggplot(ratings, aes(x = viewers_7day, fill = channel)) +
geom_histogram(binwidth = 1,
color = "black")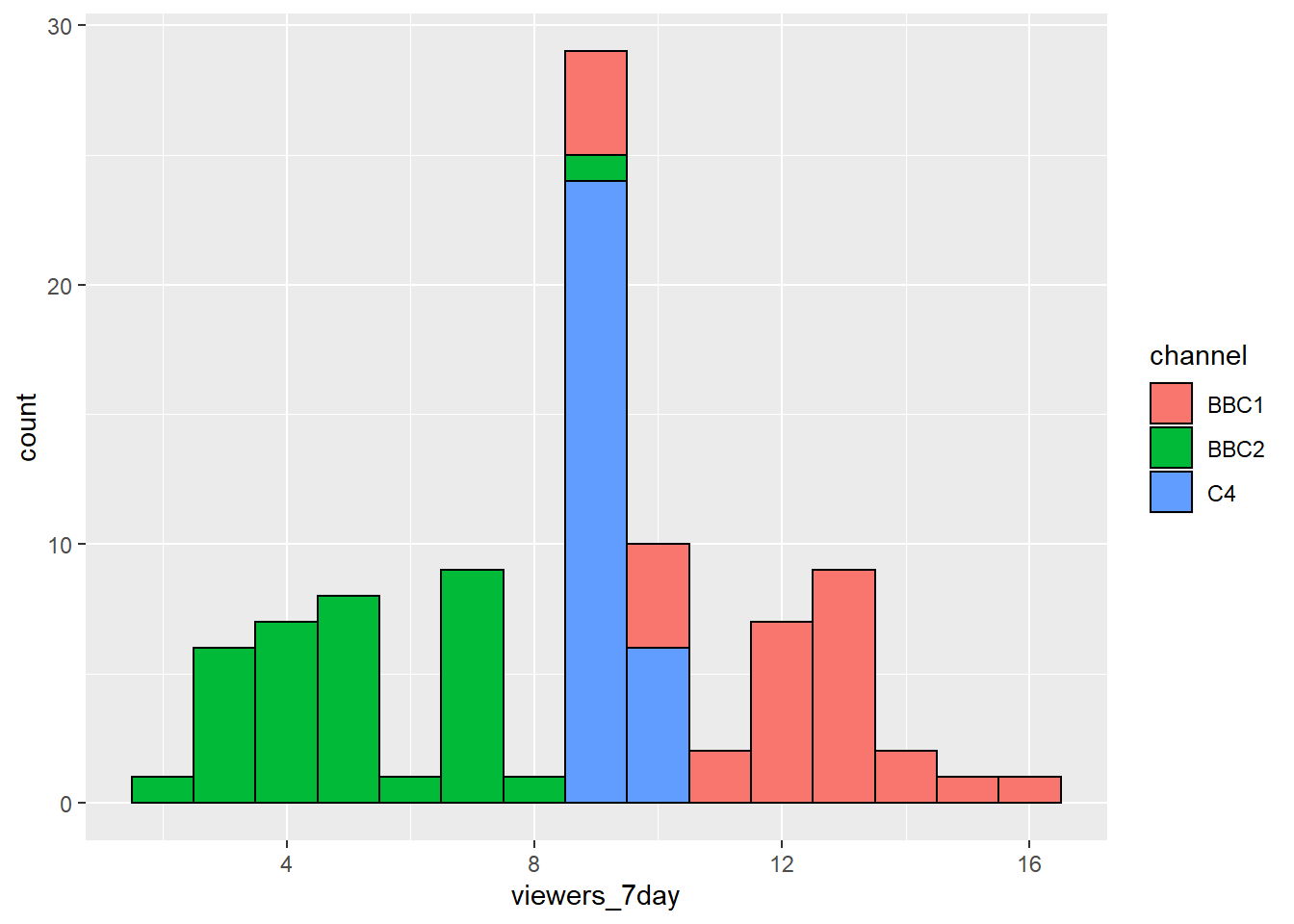
Figure 4.3: Histogram with categories represented by fill.
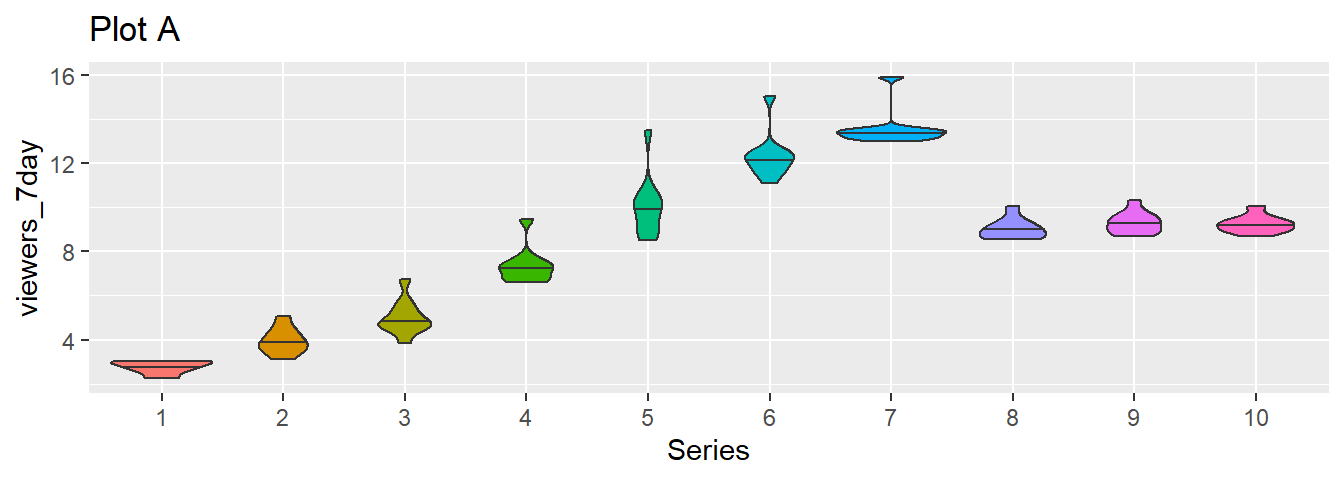
4.4.2 Violin plot
Another way to compare groups of continuous variables is the violin plot. This is like a density plot, but rotated 90 degrees and mirrored - the fatter the violin, the larger proportion of data points there are at that value.
ggplot(ratings, aes(x = channel, y = viewers_7day)) +
geom_violin() +
ggtitle('scale = "area"')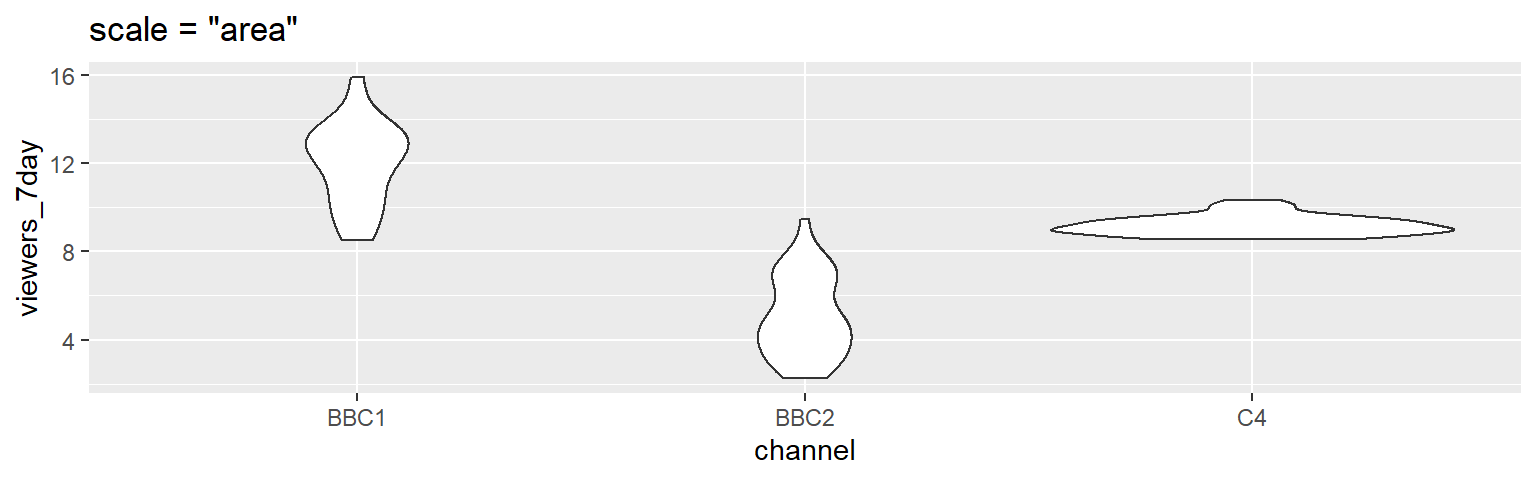
Figure 4.4: The default violin plot gives each shape the same area. Set scale='count' to make the size proportional to the number of observations.
ggplot(ratings, aes(x = channel, y = viewers_7day)) +
geom_violin(scale = "count") +
ggtitle('scale = "count"')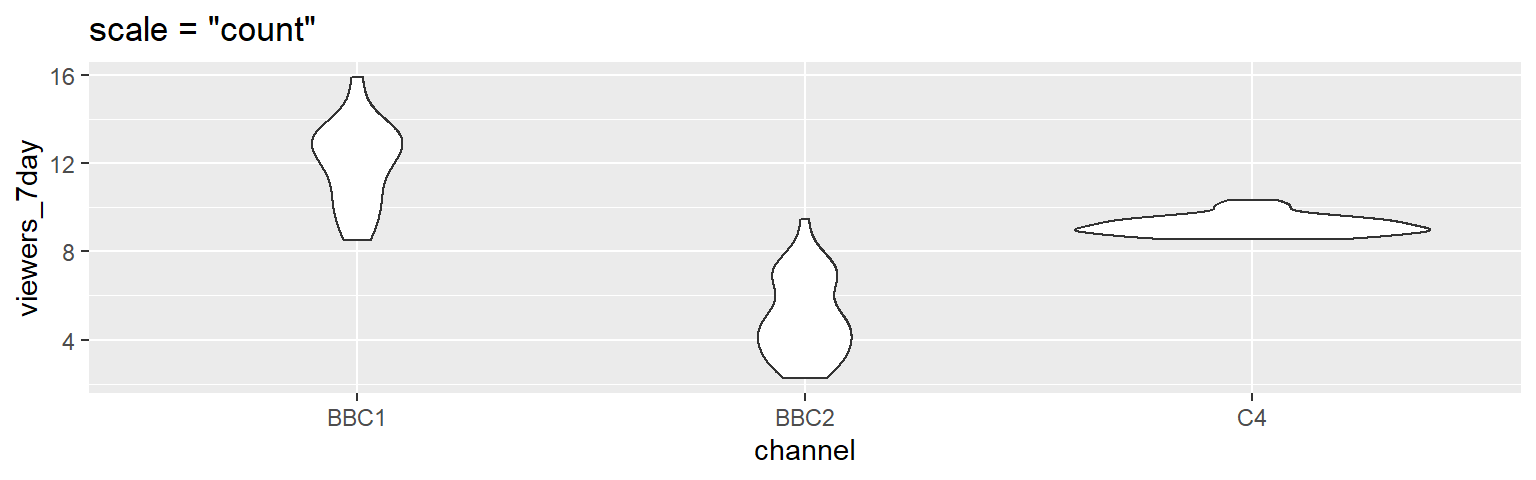
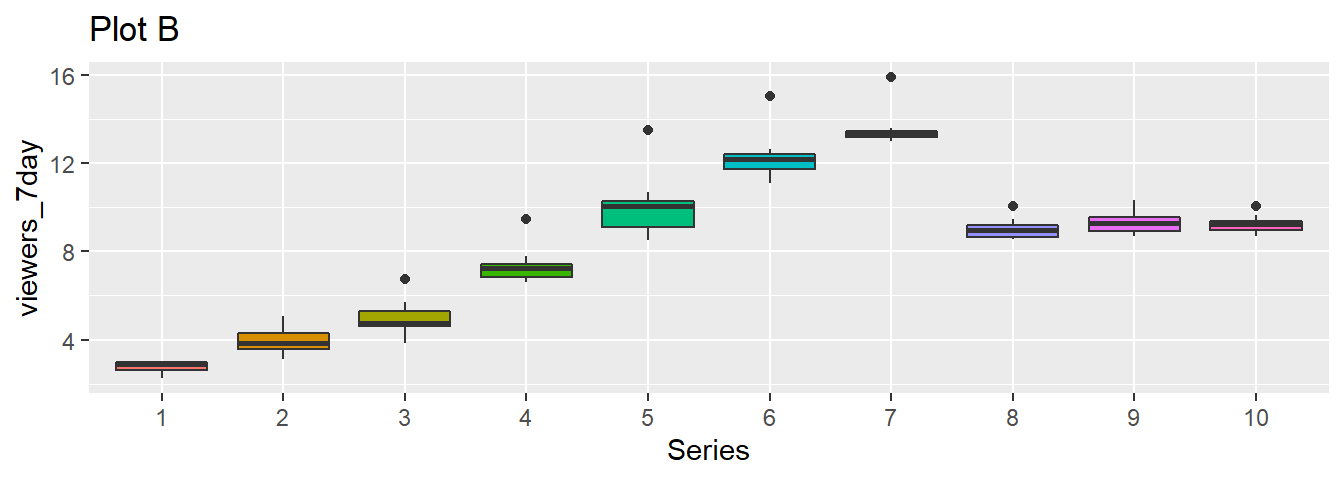
4.4.3 Boxplot
Boxplots serve a similar purpose to violin plots. They don't show you the shape of the distribution, but rather some statistics about it. The middle line represents the median; half the data are above this line and half below it. The box encloses the 25th to 75th percentiles of the data, so 50% of the data falls inside the box. The "whiskers" extending above and below the box extend 1.5 times the height of the box, although you can change this with the coef argument. The points show outliers -- individual data points that fall outside of this range.
ggplot(ratings, aes(x = channel, y = viewers_7day)) +
geom_boxplot()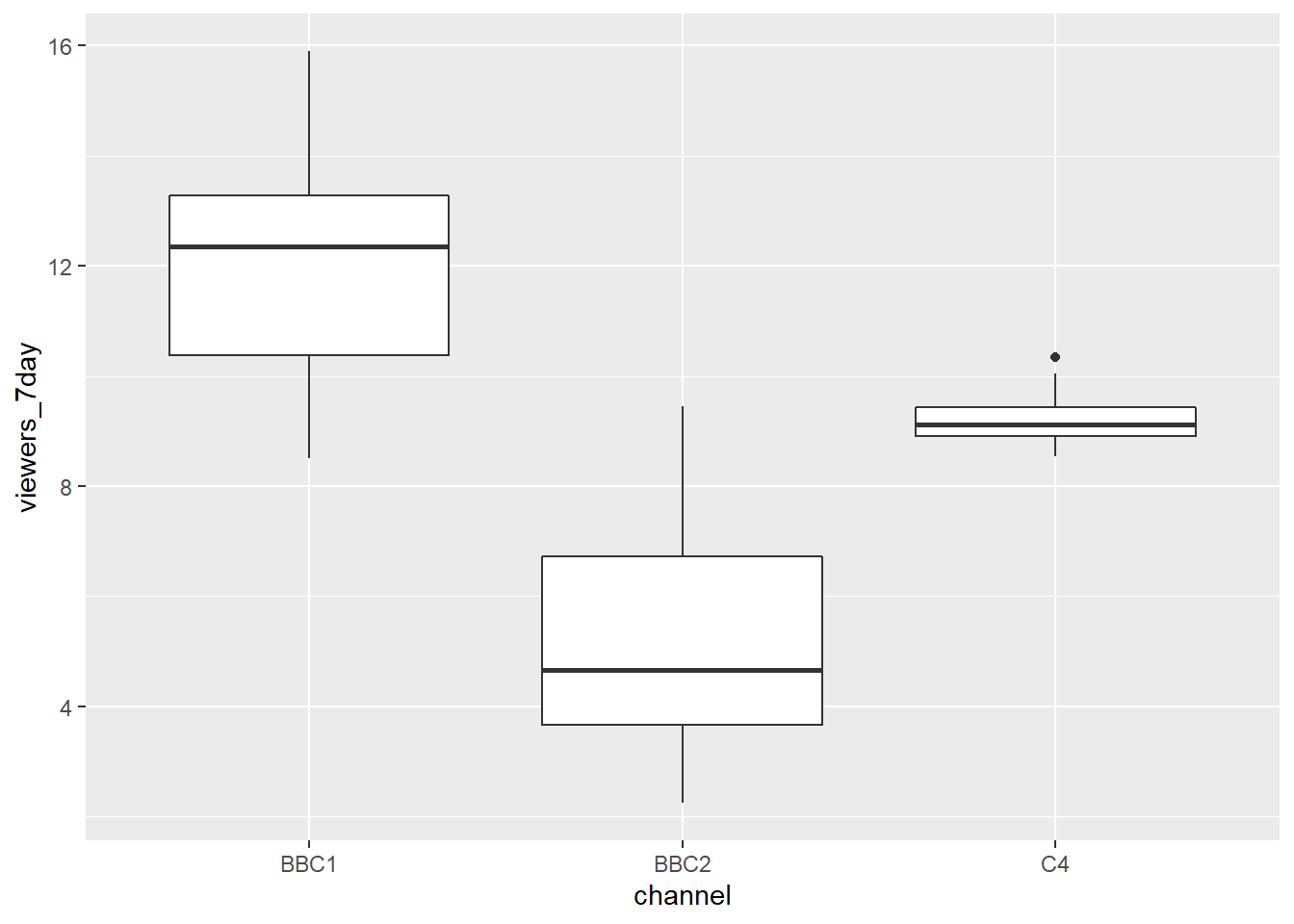
Figure 4.5: Basic boxplot.
4.5 Two continuous variables
When you want to see how two continuous variables are related, set one as the x-axis and the other as the y-axis. For example, what if we want to see the changes in ratings over the episodes/series in chronological order.
4.5.1 Scatterplot
The function to create a scatterplot is called geom_point().
ggplot(ratings, aes(x = ep_id, y = viewers_7day)) +
geom_point()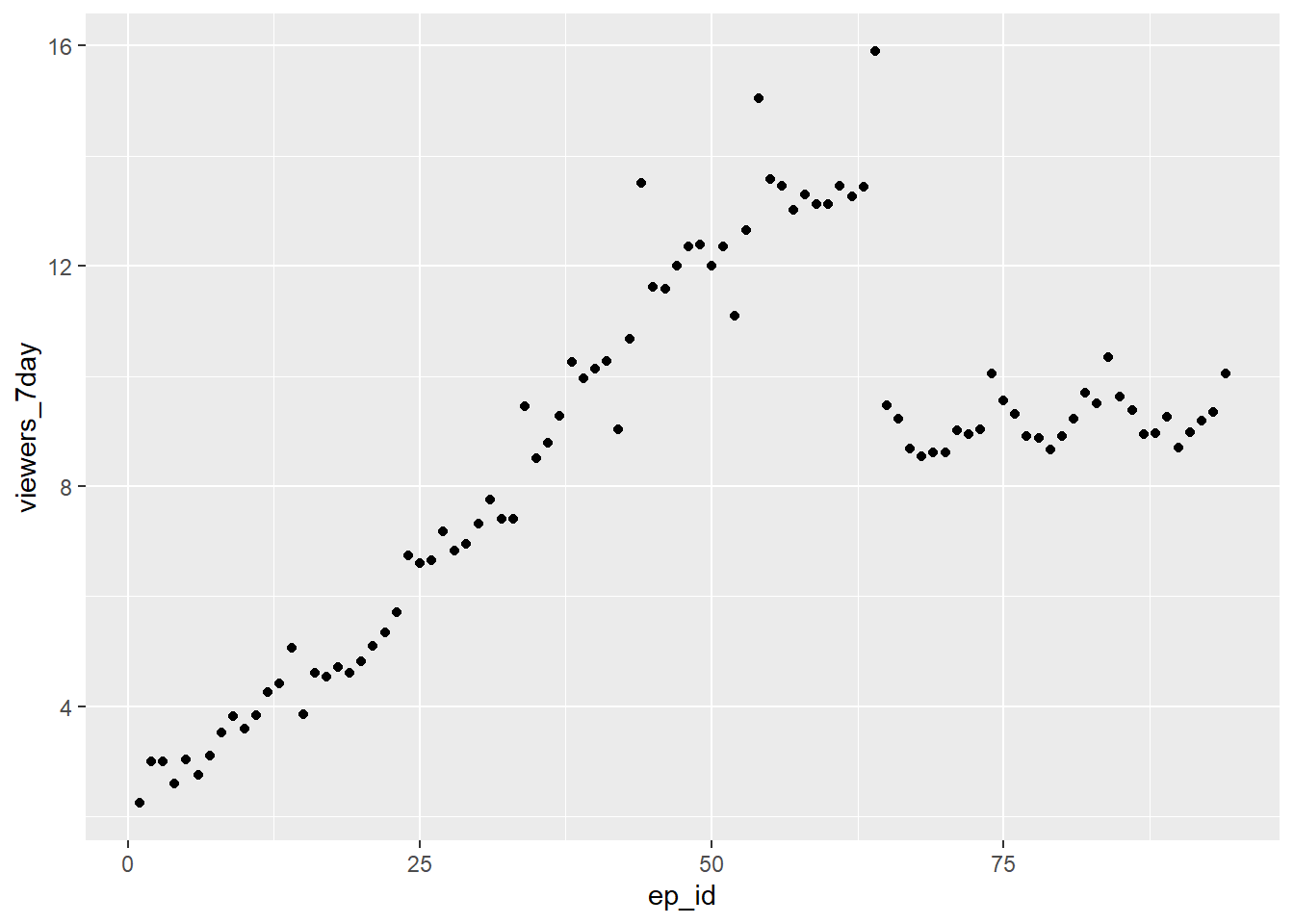
Figure 4.6: Scatterplot with geom_point().
- Edit and run the above code to join up the points in the scatterplot by adding the function
+ geom_lineand then modify the code further to remove the points
ggplot(ratings, aes(x = ep_id, y = viewers_7day)) +
geom_point()+
geom_line()+
ggtitle("Scatterplot with both points and lines")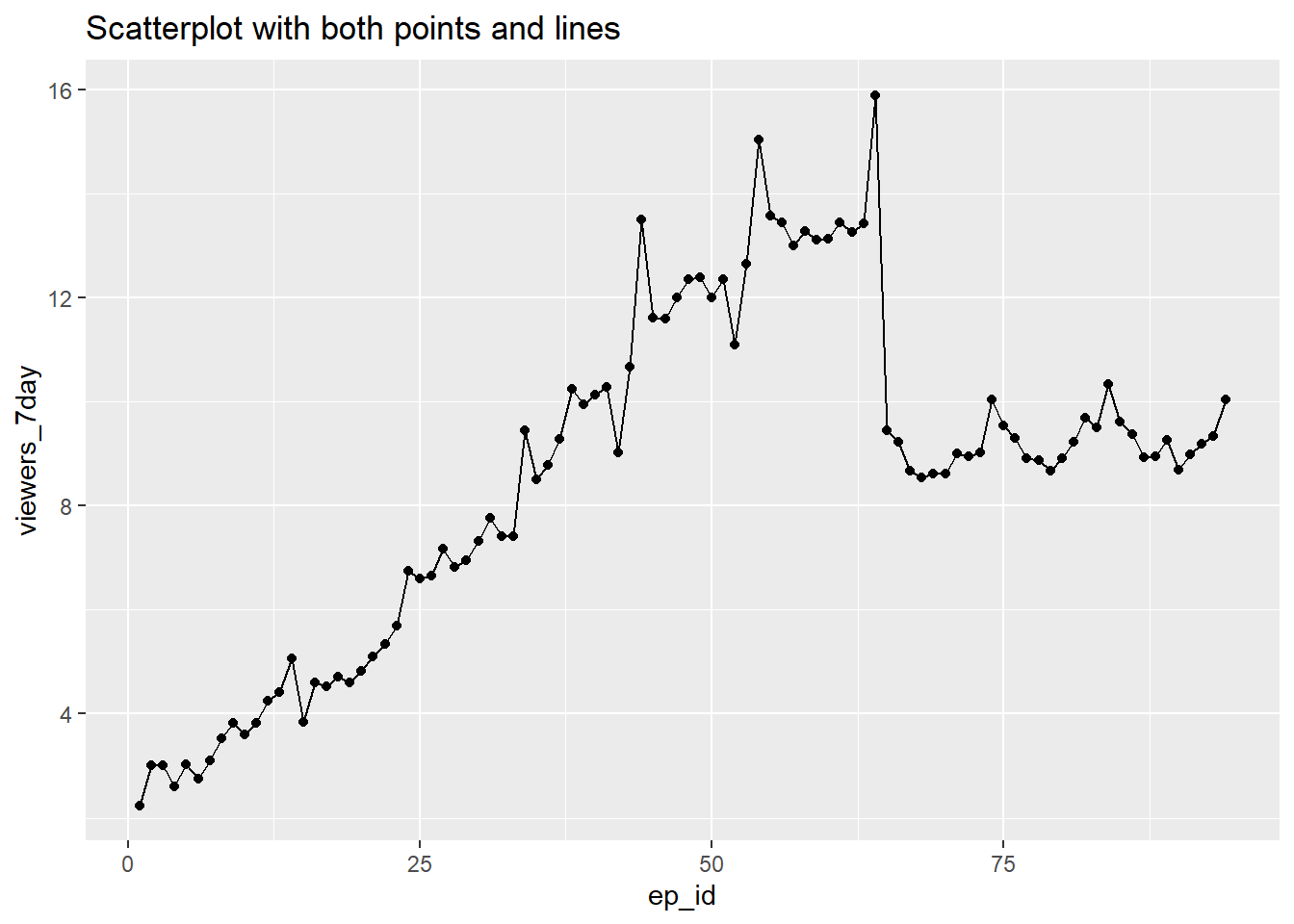
ggplot(ratings, aes(x = ep_id, y = viewers_7day)) +
geom_line()+
ggtitle("Scatterplot with just lines")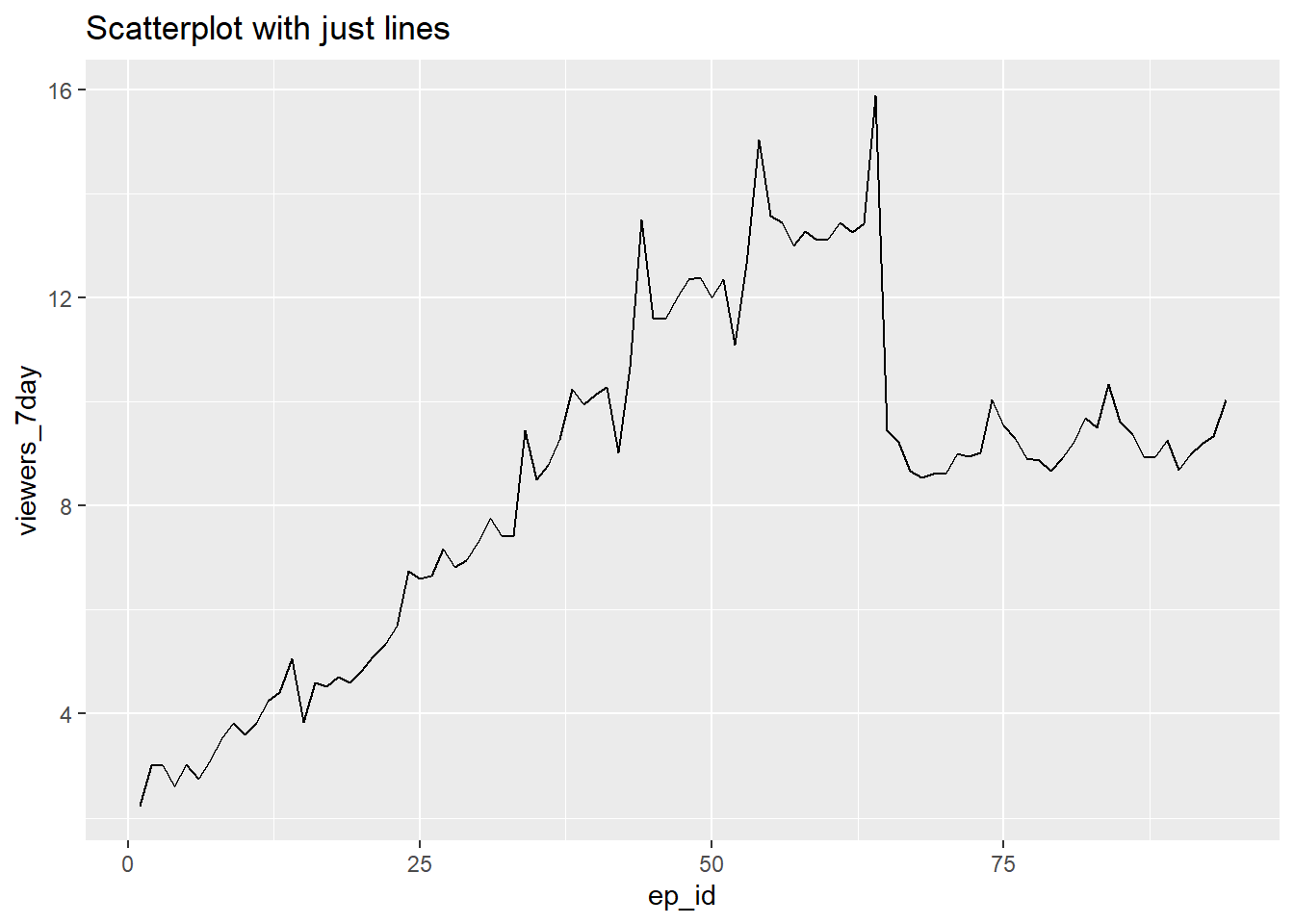
These plots show each individual episodes' ratings and are perhaps more detailed than we need. If we were just interested in looking at the ratings across series, then we could create summaries for each series and plot these.
- Examine and run this code to produce a lineplot of the average ratings for each series
avg_ratings <- ratings %>%
select(series, episode, viewers_7day) %>%
group_by(series) %>%
summarise(avg_viewers_7day = mean(viewers_7day)) %>%
ungroup()
ggplot(avg_ratings, aes(x = series, y = avg_viewers_7day, group=1)) +
geom_point() +
geom_line() +
ggtitle("Great British Bake Off Average Ratings")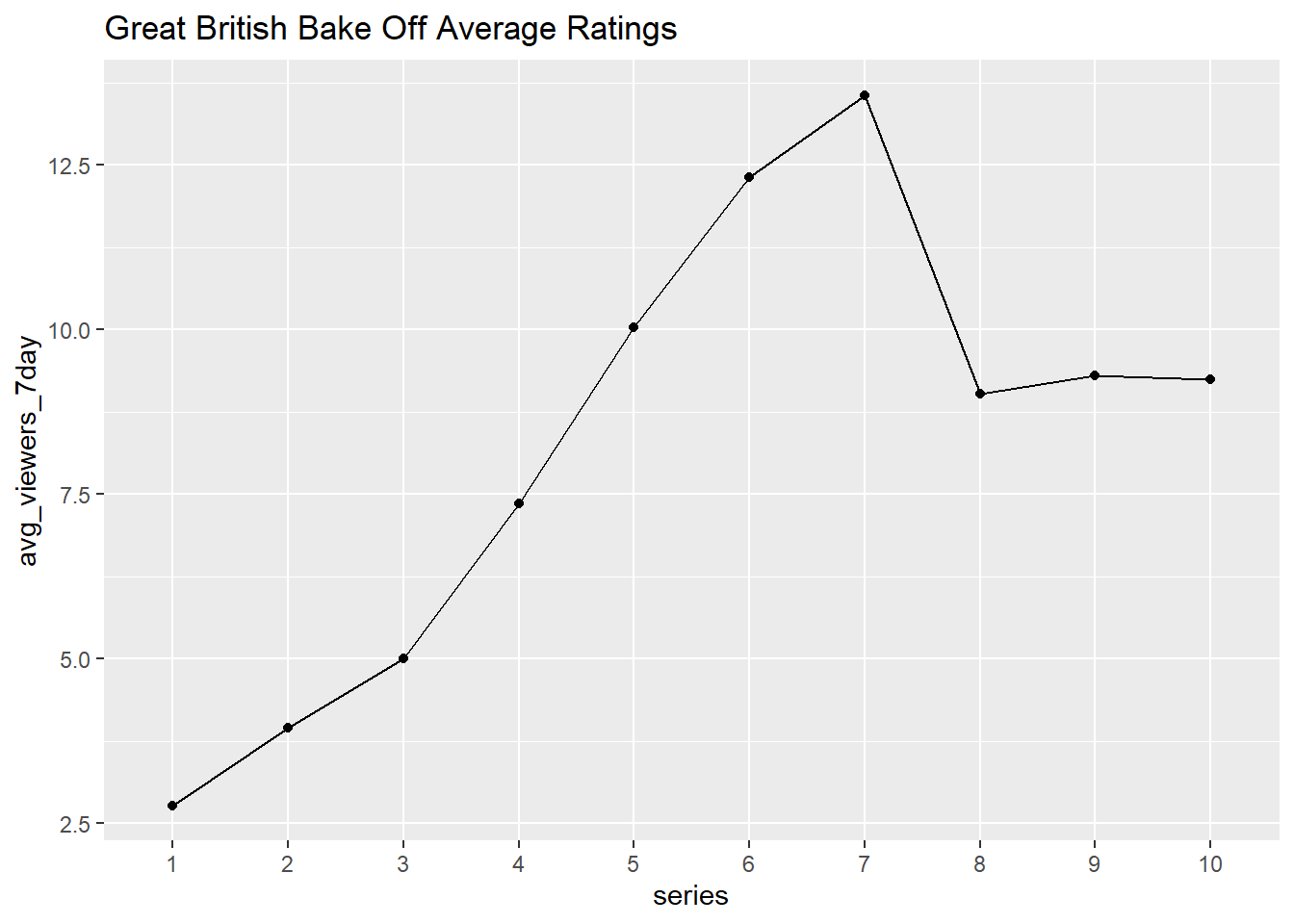
Because the x values in aes() are a factor, by default geom_line() treats each unique x value as a separate group and tries to connect points only inside each group. Setting group=1 in aes() ensures that all values are treated as one group (and therefore connected by lines using geom_line()).
4.6 Two continuous variables and a categorical variable
It is often the case that we are interested in relationships between more then two variables.
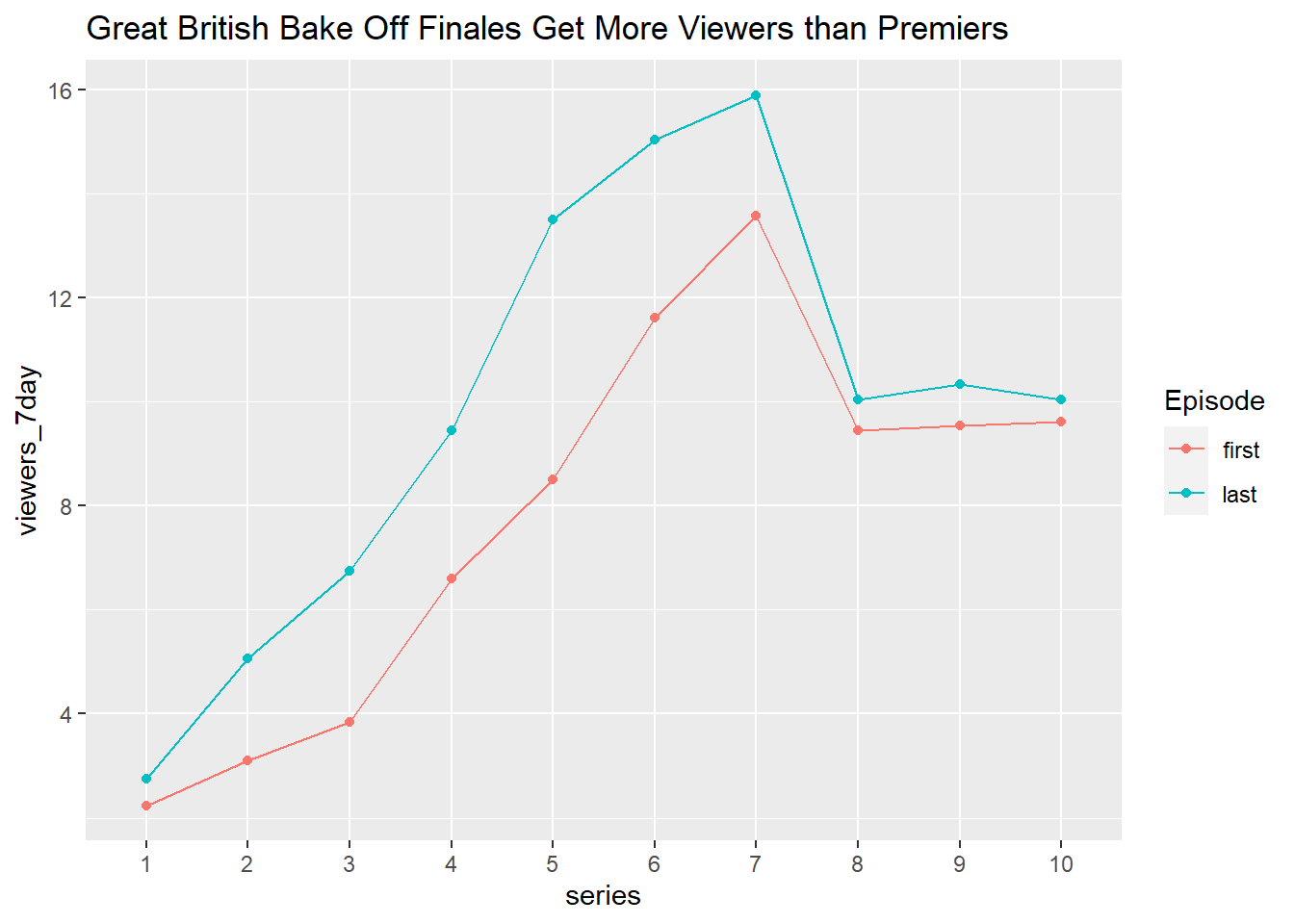
The code below illustrates how to build more complex graphical summaries, in this case number of viewers of the first and last episode in each series.
- You do not need to produce this plot but have a look and see if you can follow the code that is used to create it.
plot_data <- ratings %>%
select(series, episode, viewers_7day) %>%
group_by(series) %>%
filter(episode == 1 | episode == max(as.numeric(episode))) %>%
mutate(episode = recode(episode, "1" = "first", .default = "last")) %>%
ungroup()
ggplot(plot_data, aes(x = series,
y = viewers_7day,
color = episode,
group = episode
)) +
geom_point() +
geom_line() +
ggtitle("Great British Bake Off Finales Get More Viewers than Premiers") +
labs(color = "Episode")